La tarification classique des produits d’assurance auto repose sur les caractéristiques de l’assuré (âge, catégorie socio-professionnelle, coefficient de réduction – majoration), du véhicule (modèle, année, motorisation) ou encore de la localisation géographique de l’assuré (zonier administratif).
L’approche que nous avons mise au point pourrait s’appeler la « trajification », fusion des termes trajet et tarification. Elle offre aux assureurs une perspective supplémentaire d’ajustement de leurs tarifs.
Cette approche s’appuie sur l’historique d’accidentologie des trajets domicile-travail des assurés : c’est l’itinéraire qui concentre le risque RC – responsabilité civile – des assurés. A partir des données d’accidentologie de ces trajets ainsi que d’une catégorisation des routes réalisée au préalable sur des données marché – afin de préserver la mutualisation des risques –, un coût kilométrique est calculé pour chaque trajet d’un portefeuille donné et les primes sont ajustées en conséquence pour chaque individu du portefeuille.
Plus précisément, les données de marché permettent de former des catégories de route de même profil de risque et de former ainsi un zonier de risque a priori. Ensuite, une approche bayésienne permet de prendre en compte l’exposition spécifique du portefeuille afin d’obtenir des mesures de sinistralité cohérente pour celui-ci. On obtient alors un zonier du risque du portefeuille plus fin ainsi que des ajustements de primes affinés pour les individus.
Une méthode d’ajustement des primes autos
Calcul de la sinistralité le long d’un itinéraire
En matière d’assurance automobile, la prise en charge des sinistres corporels en responsabilité civile implique généralement le versement de rentes viagères aux victimes ou à leurs bénéficiaires.
Le nombre d’annuités de ces rentes aura alors un impact significatif sur les provisions mathématiques de l’assureur. En partant du principe qu’un assureur peut calculer le coût moyen de ces rentes, la première étape de la méthode vise à déterminer, en se basant sur les sinistres historiques, le nombre d’annuités à assumer en cas de responsabilité de l’assuré pour toutes les victimes graves sur l’itinéraire domicile-travail.
Afin de réaliser le processus de détection des sinistres historiques le long d’un itinéraire, nous avons développé une application s’appuyant sur l’API Google Maps . Elle se nourrit de la base ONISR (Observatoire national interministériel de la sécurité routière) dans laquelle les accidents sont géolocalisés et caractérisés par la gendarmerie et calcule, pour un itinéraire donné, plusieurs indicateurs tels que le nombre de sinistres, le nombre de victimes graves ainsi que leur âge moyen. En suivant ce lien, webapp-trajification, SeaBird vous propose de tracer un itinéraire entre deux adresses et de visualiser les indicateurs de risque calculés sur cet itinéraire.
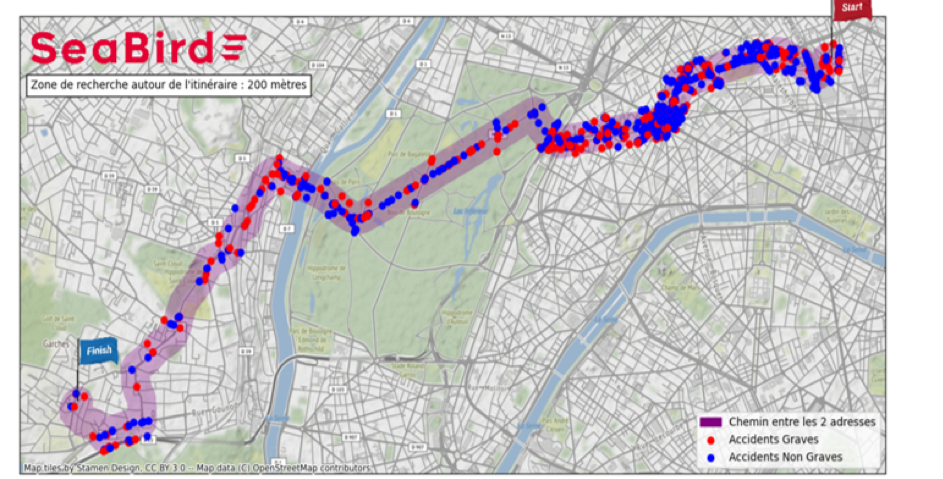
Figure 1: Illustration de la détection de sinistralité issue de la WebApp
Les indicateurs présentés sur la WebApp permettent par ailleurs l’estimation du nombre d’annuités par itinéraire.
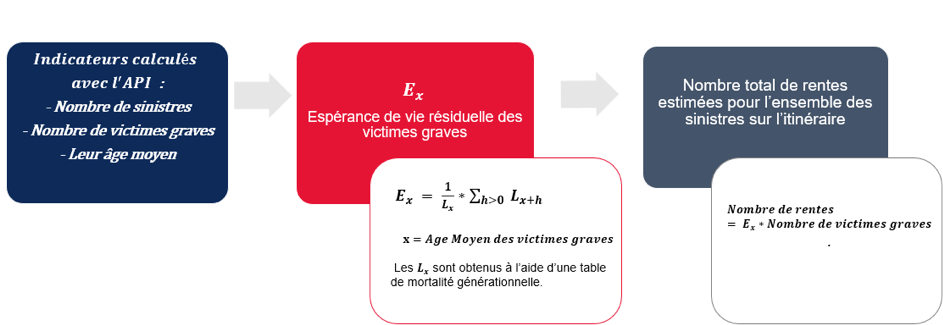 Figure 2: Calcul du nombre de rentes à partir des indicateurs fournis par l’outil SeaBird
Figure 2: Calcul du nombre de rentes à partir des indicateurs fournis par l’outil SeaBird
Cependant, cette approche, basée sur l’examen individuel de chaque itinéraire, ne suffit pas à garantir une mesure de risque non biaisée. En effet, si des mesures directes de la sinistralité historique sont effectuées sur les trajets, des inégalités de traitement risquent d’exister entre des assurés ayant pourtant le même profil de risque.
Prenons deux assurés, A et B travaillant au même endroit vivant dans la même ville.
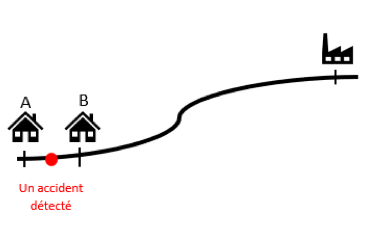
L’itinéraire de l’assuré A s’étend sur une distance de 15 km, et notre outil a identifié un accident de gravité élevée sur cet itinéraire, estimant ainsi à 60 années la durée d’indemnisation pour cet accident. En revanche, l’itinéraire de l’assuré B, qui mesure 15,5 km, n’a enregistré aucun accident.
D’un point de vue tarifaire, nous ne jugeons pas pertinent d’augmenter la prime de l’assuré A. Nous ne considérons pas que l’itinéraire de l’assuré A présente un risque significativement plus élevé que celui de l’assuré B. Par conséquent, il est nécessaire de mettre en place une mesure plus solide et objective du risque associé à un itinéraire.
Suppression des biais par classification routière
Une approche plus globale de l’évaluation du risque a donc été adoptée afin de fiabiliser le calcul de risque par itinéraire. Cette approche repose sur la classification des routes de France suivant des variables sélectionnées en fonction de leur causalité avec la gravité des accidents : la catégorie administrative de route, le volume de trafic et la topologie.
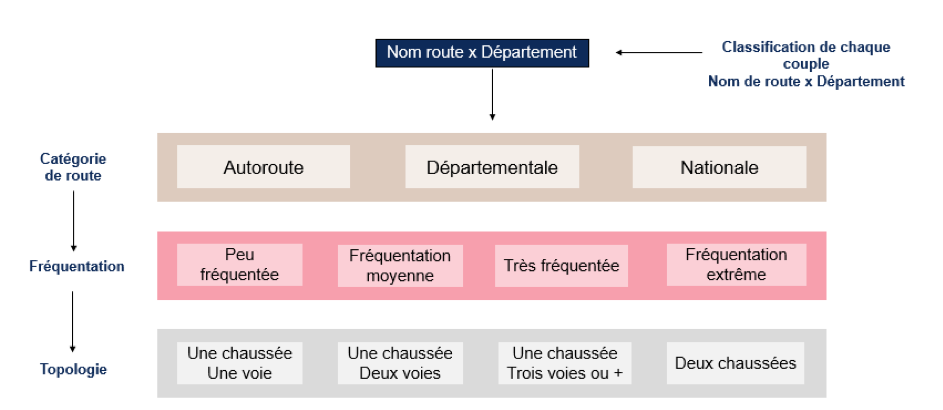
Figure 3: Procédé de classification des routes en France métropolitaine
Chaque catégorie de route (représentée par un croisement entre un département et un nom de route) désigne alors un profil de risque : on se basera sur les profils ainsi formés pour estimer le niveau de risque d’un itinéraire et éviter d’attribuer une mesure de risque directe et biaisée à un itinéraire.
Coût kilométrique
Une manière de mesurer le risque associé à un itinéraire consiste à estimer son coût kilométrique, défini comme la fréquence de rentes à assumer le long de l’itinéraire.
Le principe est le suivant :
- Attribution d’une loi de probabilité qui modélise le coût kilométrique pour chaque catégorie de route.
- Segmentation de l’itinéraire en sections par catégorie grâce à la classification présentée en amont.
- Estimation du coût kilométrique de l’itinéraire par pondération des lois des catégories en fonction du kilométrage de chaque section.
Cette approche ne se limite pas uniquement au calcul de la loi par itinéraire. De manière similaire, il est possible de calculer la loi du coût par kilomètre par département et donc de construire un zonier administratif en utilisant à la fois des données de marché et des données issues d’un portefeuille spécifique.
Tarification auto : que peut-on attendre de cette nouvelle approche ?
Score de risque et ajustement des primes
A partir de la loi du coût kilométrique pour chaque itinéraire du portefeuille, un score de risque est calculé avec l’espérance mathématique et appliqué à la prime pure afin de la majorer ou la minorer.
Première étape : une mesure de risque est choisie (par exemple l’espérance) sur le risque décrit par les lois de sinistralités sur chaque itinéraire. Par suite, le risque mesuré est centré et normalisé par méthode min-max afin d’obtenir un score de risque qui permet d’ajuster directement une prime. La formule pour un itinéraire donné s’établit ainsi :
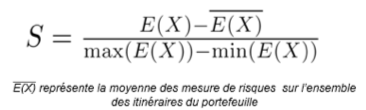 Équation 1 – Création d’un score de risque d’ajustement par normalisation
Équation 1 – Création d’un score de risque d’ajustement par normalisation
Construction d’un zonier marché
Sur la base des lois de sinistralités obtenues pour chaque catégorie de route, il est possible d’obtenir des lois de sinistralité à une échelle administrative (au département, suivant notre classification). En effet, les lois sont agrégées de la même manière que pour un itinéraire mais en pondérant par le kilométrage total des routes au sein des départements. On a alors un coût kilométrique par département.
Crédibilisation des lois sur un portefeuille par approche bayésienne
Les lois de coût kilométrique inférées reposent sur des données historiques d’accidents et sont donc susceptibles de changer au fil du temps ou face à des expositions hétérogènes sur le territoire. En conséquence, afin d’intégrer les observations d’un portefeuille d’assurés à notre connaissance a priori du risque, nous utilisons l’approche bayésienne. Le coût kilométrique annuel observé au sein du portefeuille est ainsi utilisé pour mettre à jour les lois de sinistralité des différentes catégories de route.
À l’échelle départementale, l’utilisation de l’approche de Bayes permet une personnalisation du zonier suivant les caractéristiques du portefeuille : cela permet de refléter les nuances d’exposition du portefeuille face au risque global estimé et par conséquent mieux évaluer les risques et les primes d’assurance.
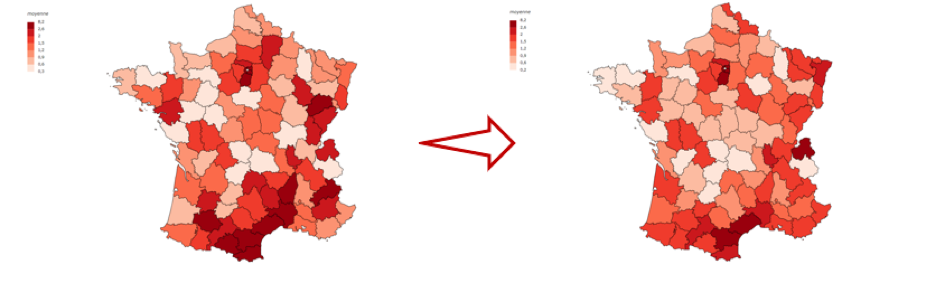 Figure 4: Évolution du coût kilométrique moyen par département
Figure 4: Évolution du coût kilométrique moyen par département