Loi Labaronne : transformer les données
En application depuis le 1er juillet 2022, la loi relative à la déshérence des contrats de retraite supplémentaire, dite loi Labaronne, impose aux assureurs d’alimenter un registre central des contrats d’épargne retraite. L’objectif ? Renforcer l’information des épargnants sur les dispositifs d’épargne retraite qu’ils détiennent. Dans la lignée de la loi Eckert sur la déshérence en assurance vie, les assureurs doivent désormais alimenter ce registre administré par la Caisse des Dépôts et Consignations (CDC). L’enjeu consiste ainsi à passer d’un format de données interne à un format structuré imposé par l’administrateur du registre. Un nouveau défi qui tient à la volumétrie des données et impose une automatisation efficace.
La Caisse des Dépôts converse en XML
Les assureurs doivent transmettre l’état de leur portefeuille à la Caisse des Dépôts sous forme d’un fichier XML bien structuré pour garantir un traitement rapide et sans encombre, et in fine l’établissement d’un registre unique pour tous les organismes d’épargne retraite. Mais qu’est-ce que le XML et pourquoi est-il essentiel de suivre les règles établies par la CDC ?
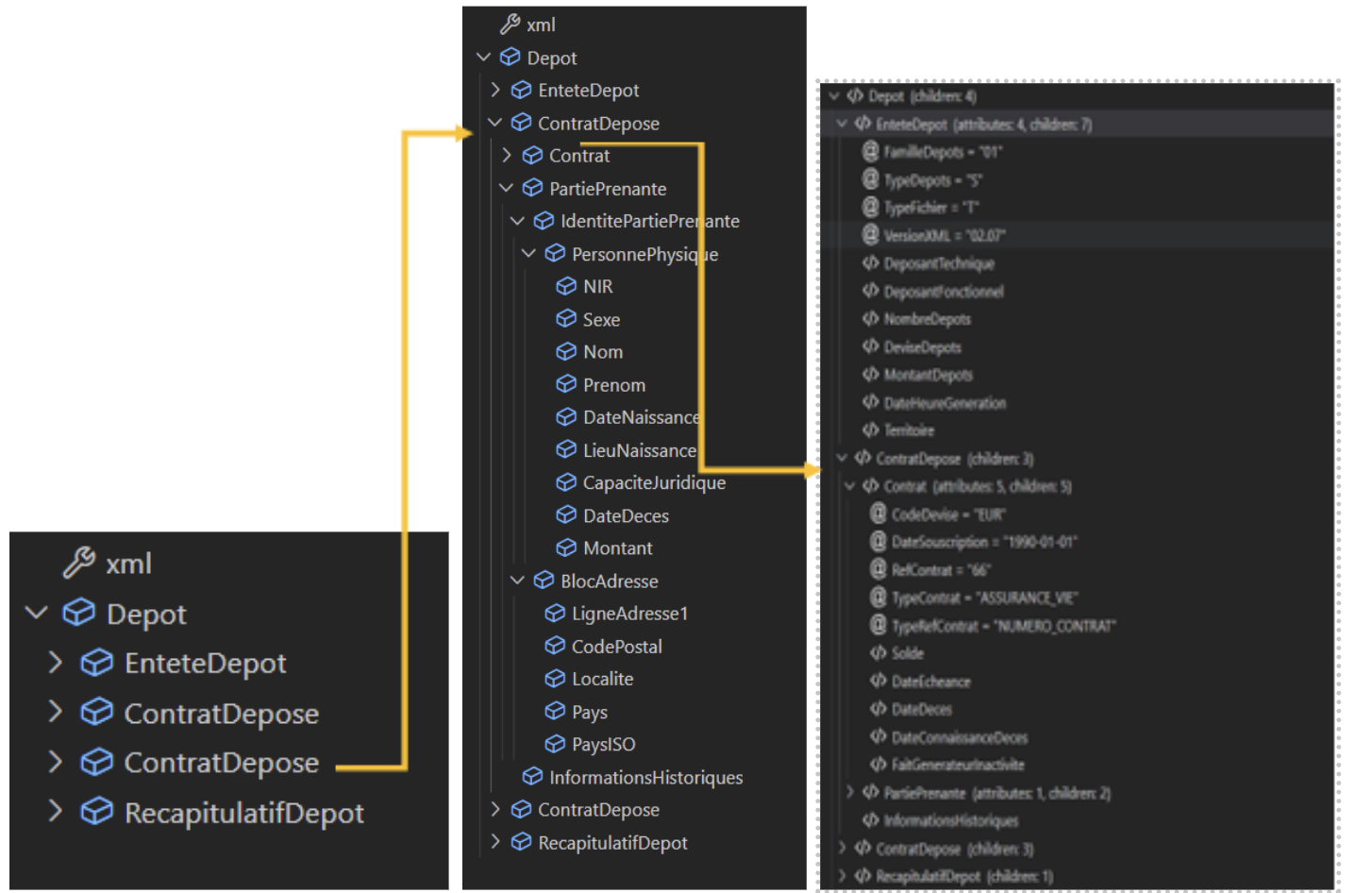
Le XML est un langage de balisage qui permet de stocker et transporter des données de manière organisée. Les données sont structurées sous forme d’éléments pouvant avoir des attributs spécifiques, semblables aux pièces d’un puzzle qui ont des couleurs et des formes uniques. Pour que notre puzzle soit complet et beau, nous devons suivre les instructions du cahier des charges technique établi par la CDC. Pour que le fichier XML soit correctement formaté, il doit suivre les règles définies dans un fichier XSD (XML Schema Definition), comme les instructions de notre puzzle. Il définit les éléments et les attributs qu’on peut utiliser, et comment ils doivent être assemblés. Il est important de respecter ces règles pour assurer une transmission fluide et efficace des contrats en déshérence.
Transformer les données : la méthode pas à pas
Comment se déroule le processus de transformation ?
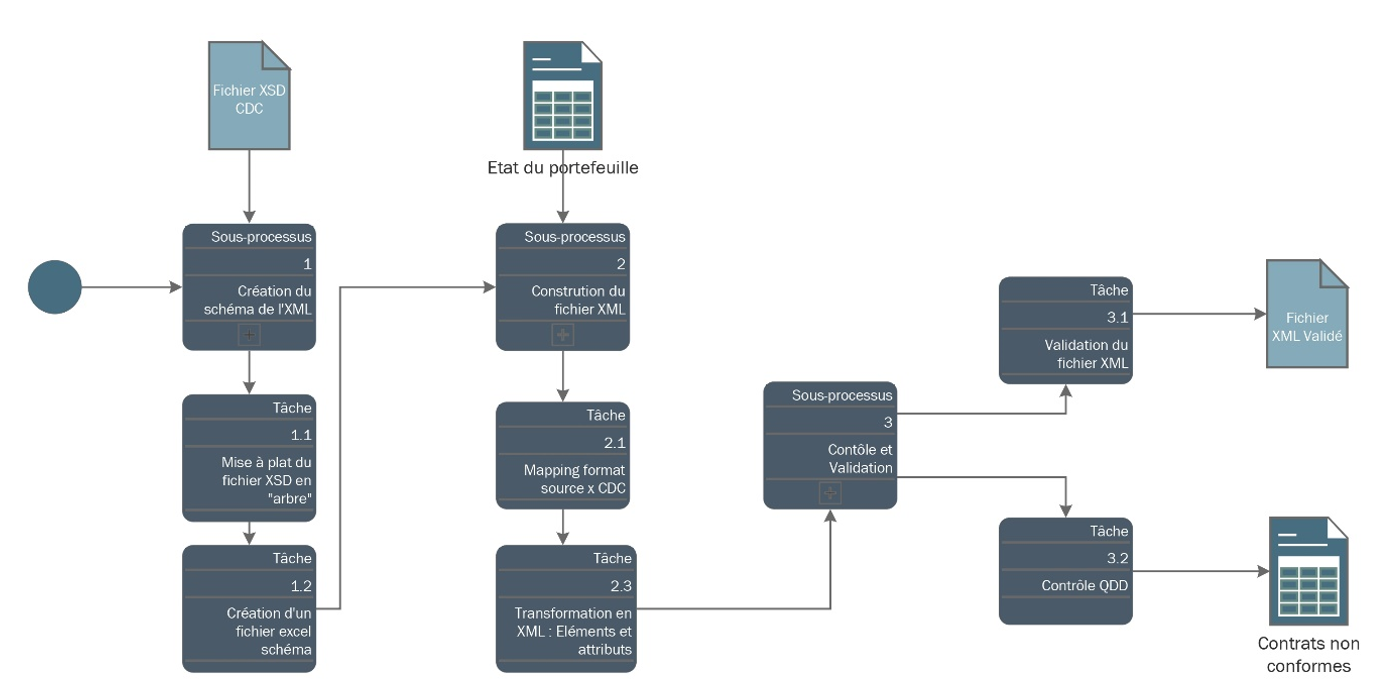
Première étape : mettre à plat le format de fichier demandé en créant un fichier schéma décryptant la structure du fichier XSD fourni par la CDC. Ce fichier permet de recréer « l’arbre » des balises et ainsi d’identifier quelle donnée est appelée par la CDC.
Etape deux : récupérer les données relatives aux contrats à exporter sous format tabulaire. Les deux tableaux sont ensuite chargés comme données d’entrée dans un logiciel d’analyse de données, Knime en l’occurrence, que nous avons utilisé pour construire le workflow de transformation.
Etape trois : établir le mapping entre le format source (fourni par l’organisme d’épargne retraite) et le format demandé par la CDC.
Une fois les données mappées, les éléments nécessaires pour créer le fichier XML (en théorie) sont réunis. Grâce aux nœuds élémentaires de transformation de données, il est alors possible de créer les éléments, définir les attributs, gérer les structures des blocs de données en manipulant listes, tableaux imbriqués et chaînes de caractères, tout en assurant le respect des conventions de nommage.
En dernière étape du flux, reste à valider le fichier XML à l’aide du fichier XSD pour garantir la conformité aux spécifications. Cette étape est réalisée automatiquement ou manuellement à l’aide d’un outil de validation de fichier XML.
Enfin, une fois exporté le fichier XML validé, il est prêt à être utilisé dans le système de destination.
Transformer les données n’a jamais été aussi facile qu’avec le no code
L’utilisation de Knime comme outil de transformation de données no-code pour le traitement des fichiers XML présente de nombreux avantages.
Tout d’abord, les fichiers XML sont souvent utilisés pour stocker des données structurées dans des formats standardisés. Avec un outil no-code tel que Knime , la transformation de fichiers de ce type est rapide et sans coût, éliminant la nécessité de recourir à un code personnalisé.
De surcroît, les ETL (Extract Transform Load) no-code sont généralement très flexibles et peuvent être facilement configurés pour transformer les fichiers XML de manière cohérente et conforme aux exigences spécifiques, et ce à travers des fonctions appliquées en chaque nœud.
Knime, comme la plupart des solutions no code, est doté de fonctionnalités de validation et de débogage intégrées, ce qui assure l’exactitude et la conformité du fichier XML en sortie présenté via une interface graphique intuitive.
De manière générale, les outils no code de transformation permettent de faciliter la collaboration entre les différentes parties prenantes, en leur fournissant une interface conviviale et un environnement de travail commun. Ces outils permettent également de simplifier les processus, d’augmenter la flexibilité et d’améliorer la qualité des données transformées.
Contrôles QDD optimisés
Ce processus de transformation de données en Knime a aussi l’avantage d’améliorer la qualité de ces données grâce à un module de QDD (qualité des données) intégré dans notre processus de transformation. Ce module, constitué de nœud élémentaires paramétrables, permet de mettre en place des contrôles de manière précise pour garantir la qualité des données. L’objectif étant d’obtenir un fichier XML exact et conforme aux exigences de la CDC.
Le contrôle qualité des données est crucial dans toute manipulation de données. Il permet de détecter les erreurs de données et les incohérences, et de supprimer les doublons, les valeurs aberrantes et les données manquantes.
En cas de non-conformité avec les règles établies, un fichier Excel recense en sortie les contrats dont certains champs ne respectent pas ces règles. Cela permet de mieux gérer les cas spécifiques en les identifiant rapidement pour les corriger de manière adéquate.
Transformer les données : processus cible
L’ensemble du processus peut être schématisé ainsi :